9.3 What is Git and GitHub?
Git is a version control system originally developed by Linus Torvalds that lets you track changes to a set of files. These files can be any type of file including the menagerie of files that typically make up a data orientated project (.pdf, .Rmd, .docx, .txt, .jpg etc) although plain text files work the best. All the files that make up a project is called a repository (or just repo).
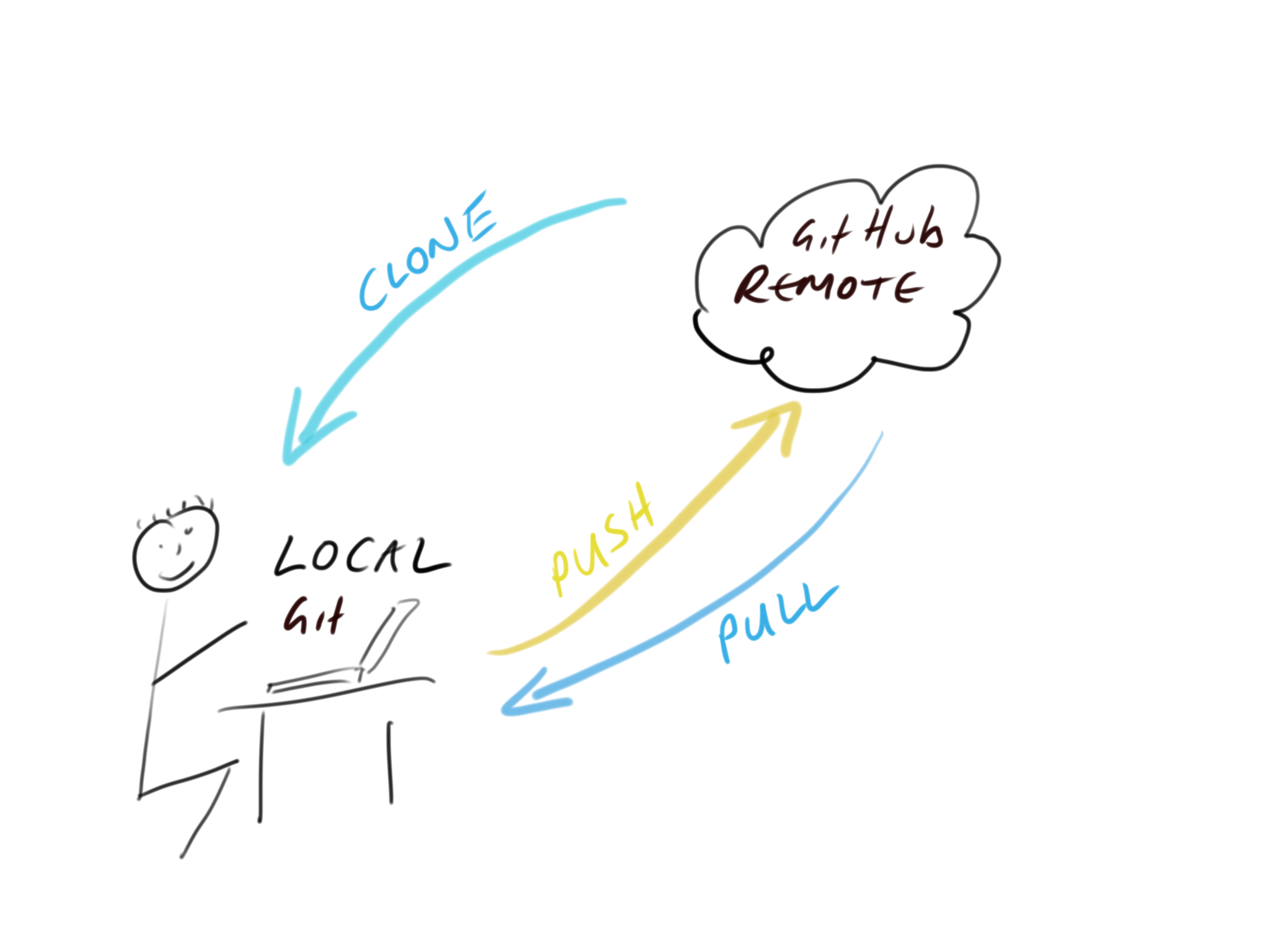
GitHub is a web-based hosting service for Git repositories which allows you to create a remote copy of your local version-controlled project. This can be used as a backup or archive of your project or make it accessible to you and to your colleagues so you can work collaboratively.
At the start of a project we typically (but not always) create a remote repository on GitHub, then clone (think of this as copying) this repository to our local computer (the one in front of you). This cloning is usually a one time event and you shouldn’t need to clone this repository again unless you really muck things up. Once you have cloned your repository you can then work locally on your project as usual, creating and saving files for your data analysis (scripts, R markdown documents, figures etc). Along the way you can take snapshots (called commits) of these files after you’ve made important changes. We can then push these changes to the remote GitHub repository to make a backup or make available to our collaborators. If other people are working on the same project (repository), or maybe you’re working on a different computer, you can pull any changes back to your local repository so everything is synchronised.